Debezium系列之:记录一次数据库某张表部分数据未同步到hive表的原因
- 一、背景
- 二、查找数据丢失流程
- 三、数据丢失原因
- 四、解决方法
一、背景
- 反馈mysql数据库中某张表的数据没有同步到hive中,现在需要排查定位下原因
数据丢失一般常见需求排查的方向:
- 数据是否采集到hdfs上
- 采集到hdfs的话,进一步去确认数据是否是因为Spark任务资源不够导致没有加载到hive表中
- 数据没有采集到的话,进一步定位分析没有采集到的原因,目前比较常见的是数据库原因导致、业务场景导致
二、查找数据丢失流程
- 首先拿一条丢失数据的id,去确认这条数据是否采集到hdfs上,发现成功采集到了hdfs上
- 观察hdfs文件生成时间,发现这张表的数据文件生成时间比较晚
- 初步判断出现了数据库主从延迟或者采集延迟,但是spark任务会等到主从延迟或者采集延迟结束才会执行,这样应该能确保不会遗漏数据,进一步确认任务执行情况
- 发现spark任务并没有出现延迟执行的情况,因此就出现了特殊情况
- 再去查看数据库中其他表的采集情况,发现其他表的hdfs数据文件生成并没有延迟,这就说明只有这张数据丢失的表产生了采集延迟,进一步排查分析这张表
- 发现丢失数据这张表近一天的hdfs文件生成时间是在同一时间点生成的,这表明近一天的数据是在同一时间采集到了hdfs
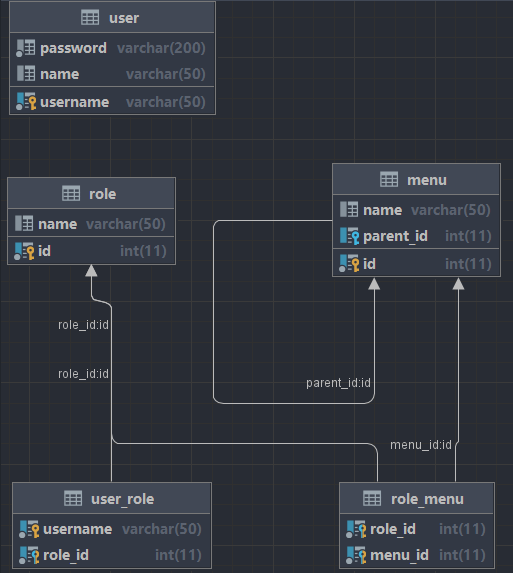
- 查看这张数据丢失表数据情况,发现这张表在不同小时的数据工用了相同的gtid,这表明这些数据来自同一个事件
- 进一步查看数据库其他表在不同小时gtid的情况,通过比较gtid,发现丢失数据这张表使用的gtid符合递增情况
- 至此,基本找到数据没有加载到hive的原因 <
![代码随想录算法训练营第74天:路径总结[1]](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fcode-thinking-1253855093.file.myqcloud.com%2Fpics%2F20240508121355.png&pos_id=img-utr7euyy-1720151187344)










![[Redis]哨兵机制](https://img-blog.csdnimg.cn/direct/9c3d423380404fa984426b726fb04415.png)